
Testing on random sets
Another testing option is to choose test sets independently at random when fitting a sequence of models. This process can be iterated any number of times and it gives some additional insight into the variability of the coefficient estimates and error statistics. It can also be instructive to turn on stepwise variable selection when doing this, to see how the model specification itself might vary. Here's the setup for fitting 10 models with 30% of the data held out at random, using backward stepwise variable selection. The displacement variable was not included in the starting set to avoid the multicolllinearity issue identified in the original model fitted to this data set.
Another testing option is to choose test sets independently at random when fitting a sequence of models. This process can be iterated any number of times and it gives some additional insight into the variability of the coefficient estimates and error statistics. It can also be instructive to turn on stepwise variable selection when doing this, to see how the model specification itself might vary. Here's the setup for fitting 10 models with 30% of the data held out at random, using backward stepwise variable selection. The displacement variable was not included in the starting set to avoid the multicolllinearity issue identified in the original model fitted to this data set.
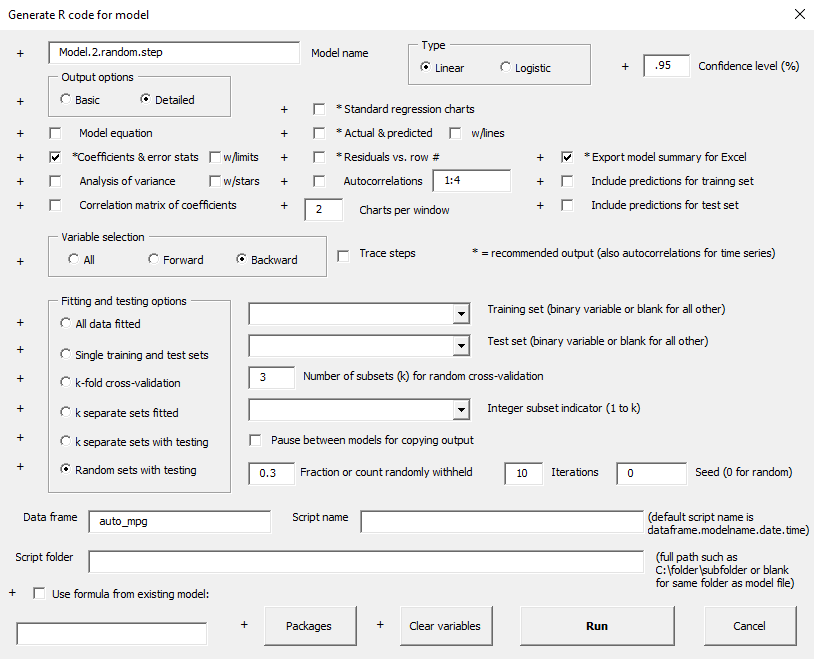
The selected models have between 4 and 6 variables (out of 7 in the starting set), and the test set RMSE's are about 4.5% larger than the training set RMSE's on average. (The average test/train RMSE ratio is 1.045.) As in the k-fold cross-validation example, there is quite a lot of variability in the relative values of RMSE between the training and tests from one iteration to another. In fact, in 4 out of the 10 iterations the test set RMSE was less than or roughly equal to the training set RMSE.
