Program features

General
- Free add-in for Excel that performs multivariate descriptive data analysis and linear and logistic regression analysis with a novel output and interface design.
- Written in Visual Basic, the program file is less than 1M in size and it can be launched on an as-needed basis or placed on the Excel add-ins menu.
- The linear regression version now runs on Macs (in the native Mac version of Excel) as well as on PCs. A separate version that includes logistic regression runs only on PCs but can be used on Macs with virtualization software such as VMware.
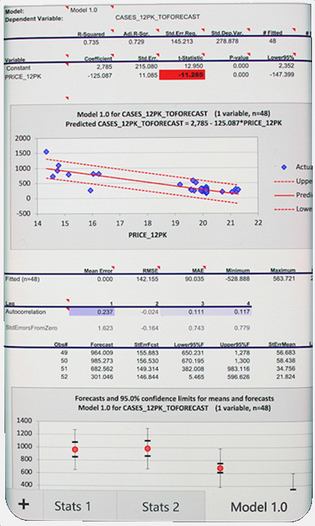
- The new versions feature a 40-button ribbon interface, pictured above, whose features are unique among Excel add-ins (and regression software more generally) in terms of the support that they provide for easy navigation of the model space, comparing the fine details of models, documenting and presenting the results, and taking full advantage of touchscreen technology. A fully detailed analysis can be driven with one finger on a tablet computer, and the output is easily viewed and navigated on a smart phone. See the screen shot at the bottom of this page for an example of a regression output worksheet as viewed on a phone.
- The program is designed to support and and encourage best practices of data analysis by making it easy (even fun) to do the right things. It makes a good complement to other statistical software for anyone who is at least an occasional Excel user.
- It provides abundant table and chart output that is presentation-quality and can be generated either in editable Excel format or in low- or high-resolution fixed formats.
- The regression procedure includes pop-up documentation of the analysis options as well as detailed teaching notes that can be embedded in model worksheets in the form of cell comments. Thus, it is self-teaching to a significant extent. There are currently about 10,000 words of such internal documentation. The teaching notes are going to be refined and expanded over time (we welcome your input), and they could be customized to fit a school or instructor.
- It includes some other novel features for instructors that make it easy to review, authenticate, and grade very large numbers of student files.
- RegressIt can be operated simultaneously with other Excel statistics add-ins such as XLSTAT, Analyse-it, StatTools, SigmaXL, and XLMiner, effectively adding more menu options and better-designed tables and charts to their regression procedures.
- RegressIt also reads and writes R code for linear and logistic regression, so it can be used as a front end for running models in R or a back end for producing additional table and chart output in Excel format, with no typing of R code.
- Charts are formatted in accordance with good principles of statistical graphics, they are uniquely titled and descriptively labeled, they have properly scaled axes, and their point sizes are adjusted for the size of the data set. (Excel's default formatting is not used.) As Excel chart objects, they can be instantly enlarged to fill the screen by moving them to individual worksheets, and they are subject to further editing or active linking after being copied to Word or Powerpoint files.
- Numbers are formatted with enough decimal places but not too many, and they are lined up to the best degree possible in tables. An advantage of the Excel environment is that numbers are stored in full precision within cells, so they do not need to be formatted to show many more digits than are useful.
- Variables are defined as named column ranges, they can be up to 1M rows in length on a PC and up to 120K rows long on a Mac, and they can have descriptive names up to 30 characters in length. All tables, charts, and dialog boxes are formatted to accommodate long variable names with full visibility.
- The output is well-organized and well-labeled for navigation, presentation, and audit trail purposes. The results of each data analysis or regression analysis are stored on a separate worksheet with an identifying analysis name that appears in all table and chart titles. Default names indicate the chronological sequence (Stats 1, Stats 2, ..., Model 1, Model 2, etc.) but customized names and numbering schemes can be assigned when procedures are executed. For example, a model called Product 1.2 is followed by Product 1.3 by default.
- A separate model summaries worksheet provides an audit trail for all regression analyses performed in the same workbook, including a table of side-by-side comparisons of model statistics.
- The audit trail information on individual output worksheets and the model summaries worksheet includes the computer name as well as the run time, which is useful for tracking work performed by different individuals and/or in different locations and for authenticating student work.
Descriptive statistics procedure
- Produces a table of descriptive statistics and correlation matrix and optional series plots and scatterplots and histogram plots. Autocorrelations at user-selected lags (not necessarily consecutive) can also be included.
- Variables are sorted alphabetically by default in the table and chart arrays, but there is an option to designate a variable to list first, say, the dependent variable in a multiple regression analysis or a common predictor for several dependent variables.
- The series plots, which are stacked one above the other, can show the data as points, lines, points-and-lines, or vertical bars.
- The correlation matrix uses colors and font shading to highlight the most and least significant values, and column names are staggered down the diagonal to allow long variable names to be fully visible. When the dependent variable for a regression model is selected as the variable to list first, the first column of the correlation matrix shows its correlations with all the other variables right next to their names.
- When the squared-correlation-vs-first-variable option is used, the correlation matrix is replaced by a table of correlations and squared correlations versus the first variable. The table can be sorted on square correlation using the Filter tool, and regression variables can be pre-selected from it by using the Remove tool.
- The scatterplot matrix can be either a full square array or it can be limited to those plots in which the variable-to-list-first appears on either the X-axis or Y-axis. Each plot in the matrix is a separate Excel chart that can be independently moved, copied, re-sized, and edited.
- The titles of scatterplots include the correlation and either its squared value or the slope coefficient.
- Scatterplot axes are scaled so that their limits are the minimum and maximum values of the variables, to spread the points out as fully as possible, and those values (plus the midpoints of the ranges) are shown on the axis scales to provide additional summary statistics for the viewer.
- The scatterplots may also optionally include regression lines and/or center-of-mass points.
- Histogram plots also include some descriptive statistics printed on them: the minimum, maximum, and midpoint of each variable.
Linear regression procedure
- The PC version can handle over 200 independent variables and up to 1M rows of data, subject to a practical limit of around 5M cells in the data matrix. The Mac version can handle up to 125 variables and up to 120K rows of data. The R interface can be used to fit larger models in much less time on either platform.
- The regression output worksheet is formatted to place the most important information at the top with as much as possible in view at one time.
- The title of every regression table and graph is automatically labeled with the analysis name, dependent variable name, sample size, and number of independent variables. This is helpful for presentation purposes and makes it easy to trace any piece of output back to its source if it is copied elsewhere.
- R-squared and adjusted R-squared, standardized coefficients, t-statistics, F-statistics, and P-values are calculated with live formulas for educational purposes.
- Confidence limits in tables and charts are also calculated with live formulas, allowing the confidence level (stored in cell I10) to be interactively adjusted after fitting the model, which is useful for demonstrations and preparing reports.
- Standard chart output includes plots of actual and predicted values vs. row number (with confidence limits for forecasts, if any), residuals vs. observation number, residuals vs. predicted values, and a residual histogram chart. A line fit plot with confidence bands is also produced for a simple (1-variable) regression model.
- The residuals vs. observation number plot is formatted as a column chart to highlight signs and time patterns.
- Other optional chart output includes a normal quantile plot and residuals vs. independent variable plots.
- Statistical tests of residuals include the adjusted Anderson-Darling statistic and/or Jarque-Bera statistic, and, for time series data, residual autocorrelations for any lags specified by the user The significance of the normality test statistic is printed on the residual histogram and normal quantile plots, and the autocorrelation at the first listed lag can be shown on the residual-vs-observation# chart.
- When the regression procedure is launched from an existing regression model sheet, the starting variable selections are the ones used in that model, making it easy to tweak any previously fitted model and explore the model space in a systematic way.
- When the data analysis procedure is launched from an existing regression model sheet, the starting variable selections are the ones used in that model, with the dependent variable designated as the first variable, so that a descriptive data analysis report can be instantly produced to match the variables and sample used in the regression model.
- The regression model sheet includes an optional residual table which shows not only the actual and predicted values and residuals, but also standardized and absolute standardized residuals, leverage, and Cook's D. Excel's filtering tool, which is included on the RegressIt ribbon, can be used to interactively sort the table on any of the statistics in order to identify the most unusual or influential cases.
Forecasting outside the sample
- If the "Forecasts for missing or future values" box is checked, a forecast table will be included on the regression model output worksheet, and forecasts for any rows where the independent variables were all present and the dependent variable was missing will be produced automatically.
- Forecasts are displayed in a table and also plotted, together with confidence limits for means and forecasts. The actual-and-predicted-versus-observation-number chart will also show the forecasts and their confidence limits if the forecast table and chart are not hidden.
- The confidence limits shown in the forecast table respond interactively to changes of the value in the confidence-level cell at the top of the worksheet (which can be adjusted hitting buttons on the ribbon) , and they also are interactive on the charts the editable option was used,
- If the option to export predictions and residuals back to the data sheet is used, the out-of-sample forecasts are included in the column of predicted values. This can be used for later out-of-sample testing and comparisons of models on that basis.
Variable transformation procedure
- Allows variables to be easily transformed with a variety of commonly used functions and, in the case of time series data, time transformations.
- Mathematical transformations include natural log, exponential, square root, power, standardization with either the sample or population standard deviation, and creation of dummy variables from either numeric or text data.
- Time transformations include lag by k periods, difference from k periods ago, difference of natural log from k periods ago, percentage change from k periods ago, deflation at a fixed rate, and centered and trailing moving averages.
- Each created variable is automatically assigned a descriptive name that concatenates the variable name and the transformation, such as X.LN for natural log of X or X.LAG1 for X lagged by 1 period, and it is stored in a new column that is inserted immediately to the right of its parent variable. This provides a clear audit trail and also ensures that the transformed variables appear adjacent to their parent variables when their names are alphabetically sorted in tables of statistics or coefficient estimates or in chart arrays.
- This tool can be used to untransform predictions for transformed variables and to recalculate errors in real units. For example, predictions for logged variables can be exponentiated for comparison to the original values.
Model summaries worksheet
- Contains side-by-side comparisons of summary statistics and coefficient estimates (with P-values) for all regression models fitted in the same workbook. This serves as an audit trail for the contents of the workbook as well as a tool for easily comparing model statistics.
- Provides a well-formatted presentation of comparative results from multiple models that is suitable for directly copying into a slide or report.
- Results for models with different dependent variables are arranged in separate blocks of rows, i.e., statistics are arranged side-by-side only for models fitted to the same dependent variable.
- Diagnostic test statistics for non-normality, multicollinearity, and residual autocorrelation are included.
- The documented regression models can be re-visited or re-launched from the specifications on this sheet with a couple of mouse clicks.
Logistic regression procedure (for PC's only)
- Fits logistic regression models in Excel with up to 16K rows of data (much larger models can be fitted on both PCs and Macs via the R interface)
- An out-of-sample testing option is provided.
- Model options include interactive tables and charts whose parameters are controlled with spinners (up and down arrows that can be clicked to increase or decrease the parameter values in pre-defined steps).
- In particular, the cutoff value for binary classification can be varied interactively after fitting a model, and you can watch the changes in the classification results (both in-sample and out-of-sample) and track your position on the ROC curve. You can use the spinner to adjust the cutoff value or type in any number between 0 and 1 increments of 0.01. The data and formula logic for this feature are self-contained within the worksheet and will work even if RegressIt is not running. A single model worksheet in a file by itself makes a good demonstration tool for properties of a logistic regression model.
- The output options include 6 charts that are very useful for visualizing and demonstrating the properties of a logistic model: ROC chart, logistic curve plot, outcome frequencies for prediction intervals in increments of 0.05, actual and predicted values versus row number, and 2 charts that show weighted averages of error rates versus the cutoff value.
R interface
- Runs linear and logistic regression models in RStudio from scripts generated by RegressIt. To generate the script, the user selects variables from the linear or logistic regression dialog box and then selects modeling options from a generate-R-code dialog box. The script file is written and a line of code for running it (a "source" statement) is placed on the clipboard. The user just needs to go to the command prompt in the RStudio console window and hit Ctrl-V and Enter to run the code to run the script. No other typing is needed in RStudio, so this feature can used by someone with no knowledge of R programming.
- The modeling options include linear or logistic regression, stepwise variable selection, and several options for out-of-sample testing or fitting separate models to different subsets of data.
- High-quality table output is produced in RStudio, much more detailed and better formatted than you get with R's native functions for linear and logistic regression.
- An option to export output to Excel is also provided. If this option is chosen, very detailed and well-formatted table output is placed on the clipboard, and the user just needs to return to Excel and hit the "Import R" button on the ribbon to have it written to a new model worksheet. The output in Excel is formatted in exactly the same way as RegressIt's own output and has many of the same interactive features (e.g., color coding of variables by sign and significance, interactive deletion of insignificant variables directly from the coefficient table, and inclusion on the analysis history list and model summaries worksheet).
- Altogether these features make R an almost invisible back end for running models in Excel with additional analysis options and also the capability to handle very large data sets. They also effectively provide a new package for generating customized regression output in RStudio.
Viewing output on cell phones
- Regressit's output is designed to be easily navigated and viewed on a smart phone. Here's a picture of a regression output worksheet as seen on a Samsung Galaxy S8. The output is readable within the screen width, the worksheet is easily scrolled, and the tabs can be used to flip among analyses. It is also possible to view the formulas and cell comments and to adjust the confidence level.