
More R examples
Some of the other fitting and testing options allow many models to be fitted at once with output that includes customized model comparison tables. One of these options is is k-fold cross-validation, which is commonly used as a test against overfitting the data. In this method, the data set is broken up randomly into k subsets of equal size (as nearly as possible), and k models are fitted. In each of them k-1 subsets are used for fitting and the remaining subset used for testing. Ideally the fitted and test error statistics should be very similar.
You can either choose randomly selected folds or preselected folds determined by an integer variables with values 1 through k. Here's a demonstration of 3-fold cross-validation with randomly chosen folds:
Some of the other fitting and testing options allow many models to be fitted at once with output that includes customized model comparison tables. One of these options is is k-fold cross-validation, which is commonly used as a test against overfitting the data. In this method, the data set is broken up randomly into k subsets of equal size (as nearly as possible), and k models are fitted. In each of them k-1 subsets are used for fitting and the remaining subset used for testing. Ideally the fitted and test error statistics should be very similar.
You can either choose randomly selected folds or preselected folds determined by an integer variables with values 1 through k. Here's a demonstration of 3-fold cross-validation with randomly chosen folds:

Note: the screen shots above and below do not reflect the most recent release of RegressIt (Nov. 14). The output is now more detailed and better formatted and it can be exported back to Excel. This page will be updated shortly.
When the line of code to run this model is pasted and executed at the command prompt, a lot of output is produced: complete results for the models fitted to all 3 sets. Here is what it looks like at the bottom, with the results for test set 3 showing. At the very bottom is a table of comparative statistics of in-sample and out-of-sample errors for the models fitted to all 3 sets. The script copies this table to the clipboard and pauses so that you can paste it elsewhere (e.g., back to the Excel file) before proceeding. If you try to replicate this example, your results will differ because of the randomization of the folds.
When the line of code to run this model is pasted and executed at the command prompt, a lot of output is produced: complete results for the models fitted to all 3 sets. Here is what it looks like at the bottom, with the results for test set 3 showing. At the very bottom is a table of comparative statistics of in-sample and out-of-sample errors for the models fitted to all 3 sets. The script copies this table to the clipboard and pauses so that you can paste it elsewhere (e.g., back to the Excel file) before proceeding. If you try to replicate this example, your results will differ because of the randomization of the folds.

Here's a demonstration of another analysis option: simultaneous fitting of different models to different disjoint subsets of the data. In this case, suppose we want to fit separate models by country of origin. To do this, the origin dummy variables must first be removed from the selections of independent variables:
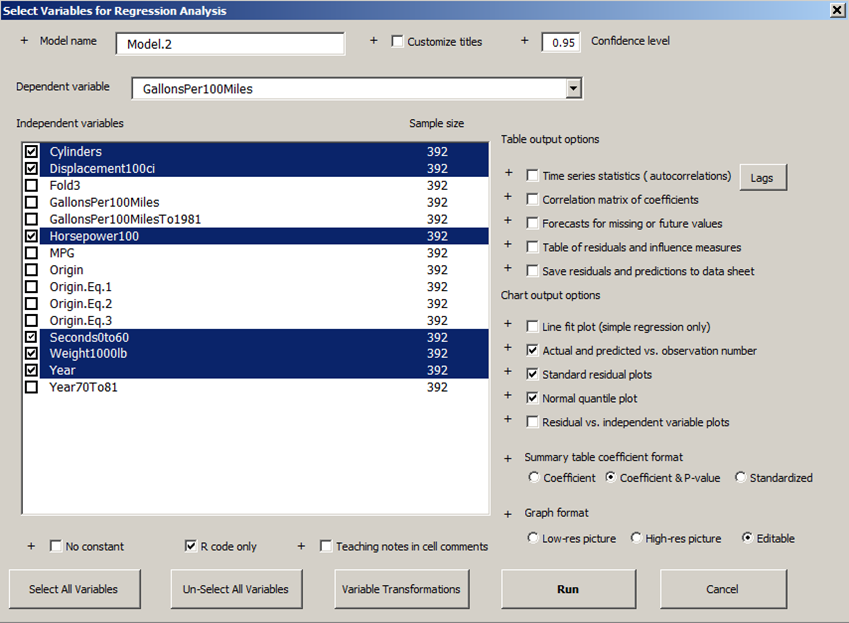
Then, in the R code options box, choose the "Separate sets fitted" option with Origin as the selection variable. Also go back to backward stepwise selection to see if the different subsets are best fitted by different sets of independent variables.
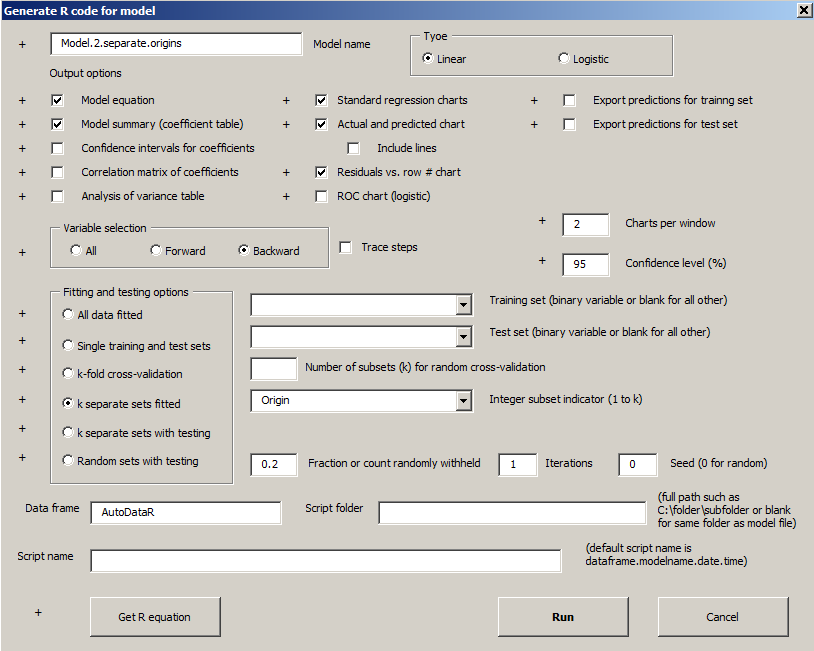
Here is an abbreviated summary of the results (some blocks of rows have been deleted). Note that all 3 models had different sets of variables selected by the backward stepwise algorithm. The models have very different RMSE's and ratios thereof, but this is not surprising given that the cars from different countries are very different in their average weight and horsepower and other attributes.
